你已经缩小到了三位最终候选人。三人都符合条件,面试表现也都不错。现在来了招聘中最难的部分:做出最终决定。
太多时候,这个决定是基于直觉、近因偏见,或者最后面试官采访的对象。其实有更好的方法。
主观比较的问题
研究表明,招聘决策常常受到认知偏见的影响:
- 近因偏见 — 偏爱你最近面试的候选人
- 光环效应 — 一个强项(名校、知名公司)影响整个评价
- 相似性偏见 — 偏好让你联想到自己的候选人
- 锚定效应 — 过度依赖你了解的第一个信息
- 对比效应 — 比较候选人彼此,而非以职位需求为标准
这些偏见不是刻意为之,而是人类本能。解决方案不是消除人的判断,而是用客观数据支持它。
构建客观比较框架
步骤1:面试前定义标准
在开始评估之前,写下:
- 必须具备的技能 — 不可妥协的要求
- 加分技能 — 可提升竞争力,但非淘汰项
- 每项标准的权重 — 技术深度比沟通更重要吗?
- 最低门槛 — 各维度“足够好”的分数是多少?
这样可以防止你无意识地调整标准去偏袒某位候选人。
步骤2:使用结构化评分
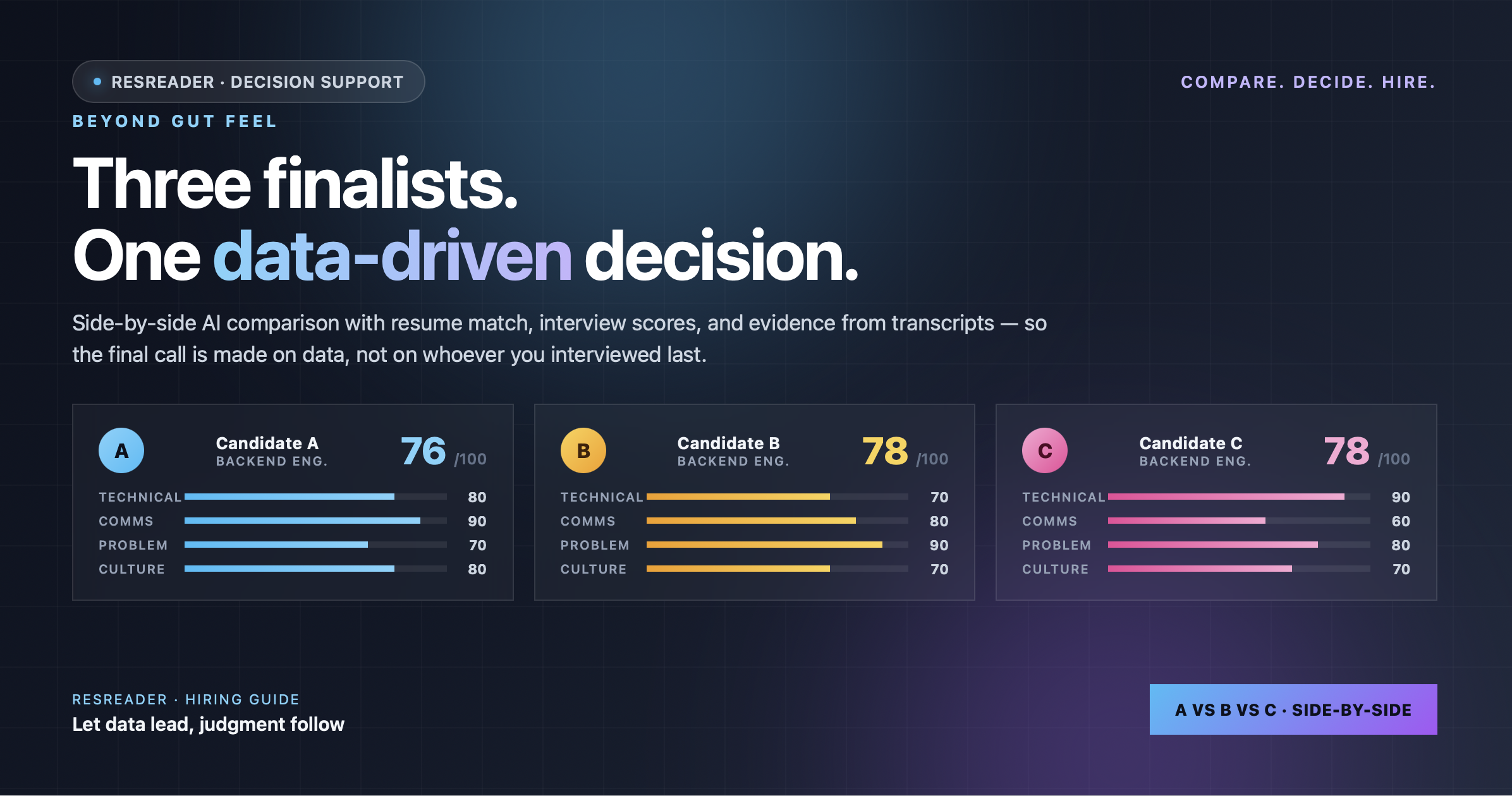
用相同的维度和标准去评分每个候选人。ResReader的AI面试能自动完成:
| 维度 | 候选人A | 候选人B | 候选人C |
|---|---|---|---|
| 技术技能(0-100) | 80 | 70 | 90 |
| 沟通能力(0-100) | 90 | 80 | 60 |
| 解决问题(0-100) | 70 | 90 | 80 |
| 文化契合度(0-100) | 80 | 70 | 70 |
| 经验(0-100) | 60 | 80 | 90 |
| 加权平均 | 76 | 78 | 78 |
分数接近时,深入细节。
步骤3:利用AI驱动的比较
ResReader的比较工具更进一步:
- 在仪表板选择2-3位候选人
- 点击**“比较”**
- AI生成全面分析,包括:
- 简历匹配分及详细拆解
- 面试表现,结合面试记录中的证据
- 跟进回复质量(如适用)
- 优势与弱点,支持具体实例
- 双方推荐意见
步骤4:添加自定义比较标准
你可以加自定义提示聚焦比较:
“请特别比较这些候选人在分布式系统经验及未来两年内成长为技术主管的潜力。”
这样你可以聚焦最符合你需求的点。
优质比较数据应具备的特征
有价值的比较不止于分数,还要回答:
对每位候选人:
- 有哪些具体证据支撑他们的评分?
- 面试中表现在哪些方面优秀?
- 哪里遇到了挑战?
- 聘用他们有什么风险?
- 他们带来了哪些独特价值?
候选人间:
- 谁在这个角色最关键的领域更强?
- 谁展现了更多成长潜力?
- 谁能够更快适应岗位?
- 各种权衡取舍是什么?
真实决策场景
场景1:分数接近,优势不同
候选人A: 技术90,沟通60 候选人B: 技术70,沟通90
问自己:这个岗位更需要哪一方面?高级后端工程师可能更看重技术深度,而客户面向的技术主管可能更注重沟通。
场景2:一项亮点,其他均衡
候选人A: 全面评分70-80 候选人B: 技术100,其他50-60
均衡型通常更稳妥。专家型适合高度技术、个体贡献角色。
场景3:履历出色,面试较弱
候选人A: 履历优秀(匹配度9/10),面试较弱(平均50/100) 候选人B: 履历一般(6/10),面试强(80/100)
面试表现通常更能预测工作成功。但要考量:候选人是否紧张?当天状况是否不佳?面试记录和录音帮助你调查。
比较历史:从过去决策中学习
ResReader会保存所有比较记录在你的比较历史中。随着时间推移你可以复盘:
- 你的比较结果对实际表现预测准吗?
- 你是否总是高估某些特质?
- 哪些比较标准对成功招聘最重要?
这形成反馈循环,逐步提升你的招聘决策。
做出最终选择
收集完所有数据后:
- 查看AI比较结果 — 理解客观差异
- 核对你的标准 — 数据是否符合预先定义的要求?
- 与团队讨论 — 共享比较报告达成共识
- 信任数据,但依然用判断力 — AI提供证据,你做决断
- 记录你的理由 — 便于未来复盘与改进
最佳招聘决策是基于信息的决策。让数据引导,判断跟随。