Quick answer: Calibration drift is when "qualified" quietly means something different depending on who's reviewing, what they saw last, and how tired they are. It's the hidden reason good candidates get cut and weak ones advance. You fix it by structuring the decision: define the must-haves once, score every candidate against the same rubric, and attach reasoning to each score so it's auditable. Done consistently, that's how you make fair, defensible hires at any volume — without slowing down.
Two recruiters review the same résumé and reach opposite verdicts. The same recruiter rates a candidate differently at 9 a.m. than at résumé #180. A hiring manager advances someone mostly because they "had a good feeling." None of these are character flaws — they're what happens when the standard lives in people's heads instead of on the page. That's calibration drift, and it quietly taxes every hire.
Why gut-feel scoring fails — even with great people
- The bar moves. Without a written standard, "qualified" floats. It drifts between reviewers, and within one reviewer across a long day.
- Recency and fatigue bias. The candidate right after a standout looks worse; the 180th résumé gets a fraction of the attention the 5th got.
- Halo effects. One impressive logo or school colors the whole read, even on dimensions it has nothing to do with.
- It's unauditable. When a decision is "a feeling," you can't review it, defend it, or learn from it later.
The result isn't just unfairness to candidates — it's worse hires, because you're optimizing for "who got a careful read" instead of "who's actually the best fit."
What structured hiring actually means
Structured hiring is simple in principle: decide what matters before you look at people, then evaluate everyone against the same thing.
- Define the must-haves up front. The non-negotiable skills and requirements for the role — set once, before the first résumé.
- Score on a fixed rubric. The same dimensions, the same scale, for every candidate. No ad-hoc criteria invented mid-pile.
- Attach reasoning to every score. A number with no "why" can't be audited or trusted. A score with two sentences behind it can.
- Use the structure to shortlist, then apply human judgment. Structure gets you a fair shortlist; people make the final call from there.
Research has long shown structured evaluation predicts performance far better than unstructured "let's just chat" hiring. The catch has always been that doing it by hand is tedious — so teams skip it under volume.
How ResReader keeps the bar fixed
ResReader builds the structure into the workflow, so consistency is the default rather than extra work:
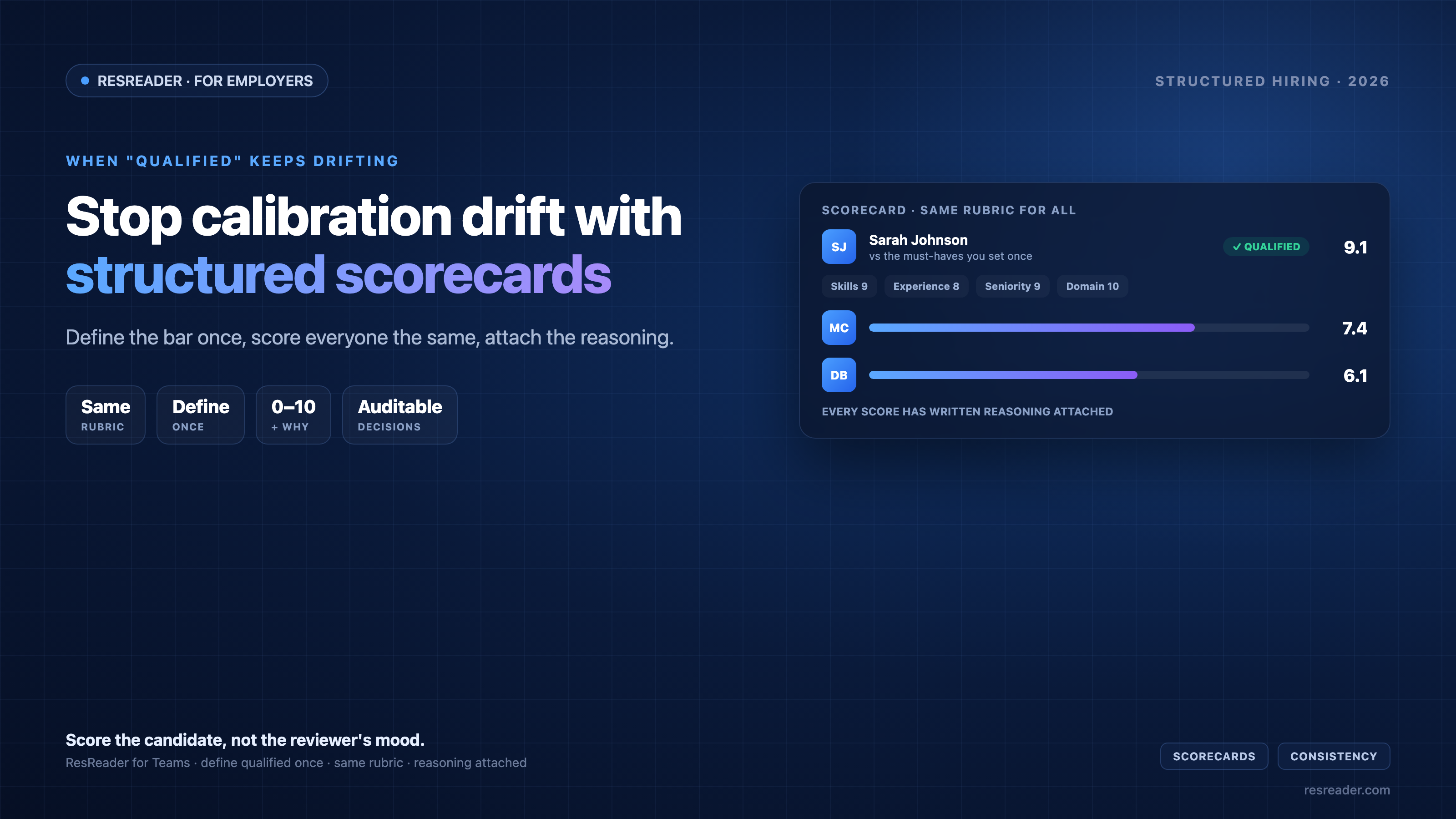
- Define "qualified" once per job. You set the mandatory skills when you create the role; every applicant is classified Qualified / Not Qualified against that same definition — no drift between reviewers.
- The same rubric for everyone. Each résumé gets an overall score (0–10) plus sub-scores (skills match, experience relevance, seniority fit, domain fit, keyword coverage). The 5th candidate and the 250th are measured identically.
- Reasoning attached to every score. Each result comes with a written 2–6 sentence assessment, so a "6" isn't a mystery — you can see what was thin and what was strong, and override it when you disagree.
- Structured interview scorecards. First-round AI interviews return per-question scores and a consistent scorecard you can sort and compare, instead of free-form notes that vary by interviewer.
- Side-by-side comparison. For finalists, an AI-generated comparison lines up ratings, interview scores, and qualified status on the same axes — steerable with a prompt, and saved so you can revisit how the decision was reasoned.
The point isn't to remove human judgment. It's to make sure judgment is applied to a shortlist that was built fairly — not to whoever happened to get read closely.
Honest limits
- A rubric is only as good as the must-haves and job description you set. Vague inputs produce vague consistency — spend the few minutes defining the bar.
- Structure reduces bias; it doesn't eliminate it. You still own the final decision, and you should still override scores you can justify overriding.
- ResReader doesn't ship formal EEO/OFCCP compliance reporting today. Structured, reasoned scoring helps you make consistent decisions, but it isn't a substitute for legal compliance tooling if you're required to file those reports.
Try it
Set the must-haves on one real role, run last quarter's applicants through it, and see whether the ranking matches the hires you actually made. ResReader's free plan includes 75 AI scans and 3 AI interviews per month, no credit card. Start free.
FAQ
What is calibration drift in hiring? It's when the definition of "qualified" varies — between different reviewers, or within one reviewer over time due to fatigue, recency, and halo effects. It leads to inconsistent, hard-to-defend decisions.
Why are structured scorecards better than gut feel? They hold the bar fixed: the same criteria and scale for every candidate, with reasoning attached. That predicts performance better than unstructured impressions and makes decisions auditable.
Does structured hiring slow things down? Done by hand, yes. Built into the workflow — define qualified once, auto-score on a fixed rubric — it's actually faster, because you're not re-litigating the standard on every résumé.
Does this remove the human from hiring? No. Structure builds a fair shortlist; people make the final call. You can override any score you disagree with.
Can I see why a candidate got a given score? Yes. Every ResReader score comes with a written assessment explaining it, plus sub-scores, so the reasoning is visible and reviewable.